소리(Sori): LLM에게 귀를 달아주는 이야기
Qwen3-4B에 Audio Encoder를 붙여 한국어 Speech LLM을 만든 과정
시작하며
한국어 Speech LLM을 처음부터 만든다고 했을 때, 데이터는 얼마나 필요할까? 훈련 다이나믹스는 어떻게 될까? 이게 이 프로젝트를 시작한 가장 큰 이유였다.
요즘 LLM에 음성 입력을 붙이는 것 자체는 이미 많은 시도가 있다. GPT-4o, Gemini 등 상용 모델들도 음성을 지원하고, 오픈소스 쪽에서도 다양한 Speech LLM이 나오고 있다. 하지만 대부분 영어 중심이고, 한국어에서의 훈련 경험을 공유하는 경우는 드물다.
그래서 직접 해보기로 했다. 설날 연휴에 H100 8대를 잡고, Qwen3-4B에 귀를 달아주는 실험을 진행했다. 한국어 음성 410만 샘플로 alignment를 시키면 어떤 loss 곡선이 나오는지, 얼마나 빠르게 수렴하는지 — 이런 감을 잡고 싶었다.
그래서 만든 게 소리(Sori)다. 한국어로 “소리”. 거창한 건 없다.
Encoder-Adapter-LLM 패러다임
Speech LLM을 만드는 핵심 아이디어는 놀라울 정도로 단순하다.
이미 잘 훈련된 Audio Encoder가 있고, 이미 잘 훈련된 LLM이 있다. 이 둘을 연결하는 작은 Adapter(Projection Layer)만 학습시키면 된다.
이 접근은 사실 새로운 게 아니다. Vision 쪽에서 LLaVA가 CLIP Vision Encoder와 LLM 사이에 Linear Projection 하나를 두고, Encoder와 LLM은 Frozen한 채로 Projection만 학습시켜서 Visual Instruction Following을 가능하게 한 것과 같은 패러다임이다. Audio 쪽에서는 Qwen2-Audio가 Whisper Encoder와 Qwen LLM 사이에 Linear Projection을 두는 구조를 사용했다 (다만 Qwen2-Audio는 Stage 1에서 Encoder까지 fine-tuning한다는 차이가 있다).
Sori는 LLaVA의 Stage 1과 동일한 전략을 따른다: Encoder와 LLM 모두 Frozen, Projection Layer만 학습. 이걸 한국어 음성 도메인에 적용한 것이다.
이건 마치 한국어를 잘하는 사람과 영어를 잘하는 사람 사이에 통역사 한 명을 두는 것과 같다. 통역사만 잘 훈련시키면 둘이 자유롭게 소통할 수 있다.
아키텍처
Sori의 구조는 다음과 같다:
Audio (16kHz 한국어 음성)
↓
Mel Spectrogram (128 bins)
↓
Audio Encoder (647M params) ← Qwen3-Omni AuT, Frozen
↓
audio_proj MLP (12M params) ← 이것만 학습!
↓
Qwen3-4B-Instruct (4B params) ← Frozen (Stage 1) / LoRA (Stage 2)
↓
텍스트 출력 or Tool Call
| 컴포넌트 | 파라미터 | 역할 | 학습 여부 |
|---|---|---|---|
| Audio Encoder | 647M | 음성 → 벡터 변환 | Frozen |
| audio_proj | 12M | 음성 벡터 → LLM 입력 공간 변환 | 학습 |
| Qwen3-4B | 4B | 언어 이해 및 생성 | Stage에 따라 다름 |
audio_proj는 겨우 12M 파라미터다. 전체 모델의 약 0.25%. 2-layer MLP로 2048 → 2560 → 2560 차원 변환을 해준다. 이 작은 다리 하나가 소리와 언어를 연결해준다.
Audio Encoder는 Qwen3-Omni의 Audio Transformer를 그대로 가져왔다. 7M 시간 이상의 오디오로 사전학습된 모델이라 음성 표현력이 이미 충분하다. LLM은 Qwen3-4B-Instruct를 썼다.
한 가지 삽질한 점이 있는데, Mel Spectrogram을 추출할 때 반드시 Qwen3-Omni의 WhisperFeatureExtractor와 동일한 설정을 써야 한다. Slaney mel scale + log10 + normalization. torchaudio 기본 파라미터를 쓰면 미묘하게 다른 feature가 나와서 성능이 확 떨어진다. 이거 찾는데 시간 꽤 썼다.
Stage 1: Transcription으로 Alignment
첫 번째 단계의 목표는 간단하다: 한국어 음성을 텍스트로 전사(transcription)하는 태스크를 통해 audio_proj를 정렬(align)시키는 것이다. 입력은 한국어 음성, 출력은 해당 음성의 텍스트 전사. 이 단순한 태스크만으로도 audio_proj가 음성 공간과 LLM의 텍스트 공간 사이의 매핑을 학습한다.
Stage 1 — Alignment via Transcription
- Audio Encoder: Frozen
- audio_proj: 학습 (12M params, 전체의 0.25%)
- LLM: Frozen
- Task: 한국어 음성 → 텍스트 전사
- 데이터: 한국어 음성 410만 샘플
- Learning Rate: 1e-4
- Effective Batch Size: 1024 (8 GPU × 8 accumulation × 16)
- Steps: 6,000
- Hardware: 8× H100 80GB
학습 데이터는 총 410만 개의 한국어 음성-텍스트 쌍을 모았다:
| 데이터셋 | 샘플 수 | 비율 |
|---|---|---|
| AIHub — 회의 음성 | 2.3M | 56.3% |
| AIHub — 상담 음성 | 831K | 20.0% |
| AIHub — 심층 인터뷰 | 802K | 19.3% |
| Zeroth-STT-Korean | 102K | 2.5% |
| AIHub — 취업 면접 | 76K | 1.8% |
의도적으로 다양한 도메인의 음성을 섞었다. 회의, 상담, 인터뷰… 사람들이 실제로 말하는 다양한 상황을 커버하고 싶었다. 회의 음성이 56%로 제일 많은데, 다수의 화자가 자연스럽게 대화하는 데이터라 모델이 실제 한국어 발화 패턴을 익히기에 좋았다.
여기서 재밌는 점은, LLM 자체는 전혀 건드리지 않는다는 것이다. Qwen3-4B는 이미 “텍스트가 들어오면 텍스트를 출력한다”는 걸 완벽히 알고 있다. 우리는 audio_proj를 통해 “이 음성 벡터는 사실 이런 텍스트야”라고 LLM에게 알려주는 것뿐이다. LLM 입장에서는 그냥 텍스트 임베딩이 들어온 것처럼 느끼는 거다.
Stage 2: 음성 Function Calling
Stage 1에서 모델이 한국어를 알아듣게 되었으니, 이제 한 단계 더 나아간다. 한국어 음성이 들어오면 텍스트로 된 Tool Call을 출력하게 만드는 것이다.
Stage 2 — Function Calling (LoRA)
- Audio Encoder: Frozen
- audio_proj: Frozen (Stage 1 결과 그대로)
- LLM: LoRA (r=16, alpha=32)
- Input: 한국어 음성
- Output: 텍스트 Tool Call
- 데이터: 18K 한국어 FC 음성 샘플
- Epochs: 5
- Batch Size: 32
- Learning Rate: 2e-5
이 단계에서는 LLM에 LoRA를 적용한다. 핵심은 assistant의 tool_call 토큰만 학습시킨다는 것이다. 사용자의 음성 부분이나 시스템 프롬프트 부분은 loss에서 제외하고, 오직 모델이 생성해야 하는 function call 부분만 학습한다.
FC 데이터셋 구축
Function Calling 학습 데이터는 다음과 같이 만들었다:
Salesforce의 xLAM function-calling 데이터셋에서 질의(question) 부분을 한국어로 번역한 뒤, ElevenLabs에서 10개의 한국어 음성을 선정하여 TTS로 음성 데이터를 생성했다. 최종적으로 18K개의 (한국어 음성 질의, 텍스트 tool call) 쌍을 만들었다.
예를 들어 이런 식이다:
"서울 강남구 날씨 어때?"
↓ Sori-4B-FC 📝 Output (텍스트)
get_weather({"location": "서울 강남구"})
"내일 오전 10시에 회의 잡아줘"
↓ Sori-4B-FC 📝 Output (텍스트)
create_event({"title": "회의", "date": "tomorrow", "time": "10:00"})
한국어 음성이 들어가면 텍스트로 된 structured tool call이 나온다. STT → LLM → Function Call 파이프라인 없이 end-to-end로.
훈련 과정
8대의 H100 80GB로 훈련했다.
Stage 1 — Alignment
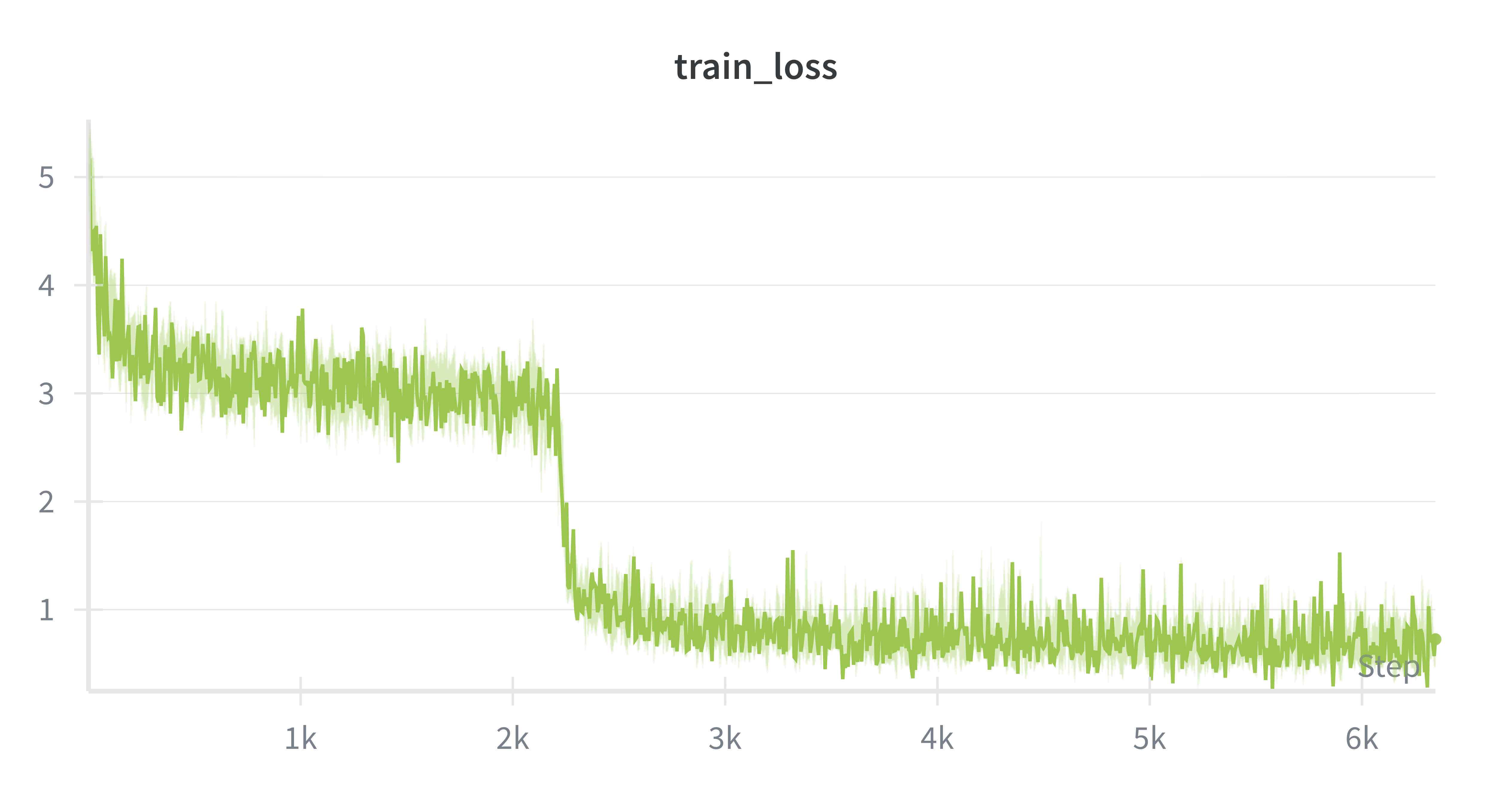
처음 2,000 스텝 동안은 loss가 3 근처에서 큰 변화 없이 머문다. audio_proj가 아직 음성 공간과 텍스트 공간의 관계를 못 찾은 거다. 그러다 2k 스텝 즈음에서 급격하게 떨어진다. 마치 “아, 이 음성 벡터가 이 텍스트에 대응하는 거구나!” 하고 갑자기 깨달은 것처럼. 이후로는 1 이하로 안정적으로 수렴한다. 6,000 스텝, 12M 파라미터만 학습하는 건데 이 정도면 alignment가 꽤 빠르게 이루어지는 셈이다.
솔직히 처음에는 “고작 12M 파라미터로 되겠어?” 싶었다. 4.7B 모델에서 0.25%만 학습하는 건데. 근데 loss가 이렇게 떨어지는 걸 보면서 확신이 생겼다. Audio Encoder와 LLM이 이미 각자의 영역에서 충분히 강력하니까, 둘을 연결하는 다리만 잘 놓으면 되는 거였다.
Stage 2 — Function Calling
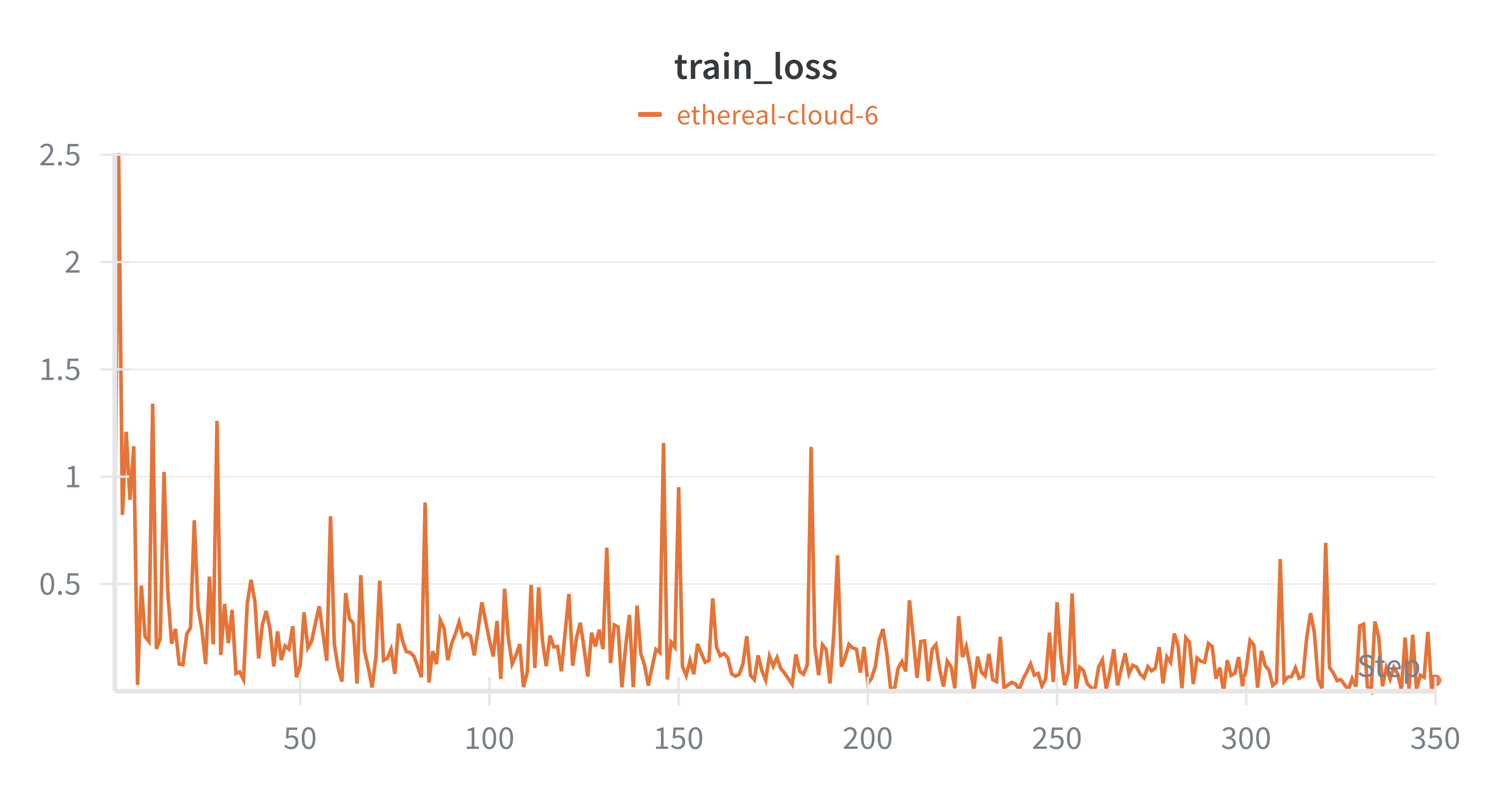
Stage 2는 더 극적이다. 350 스텝(5 에폭)밖에 안 되는데, 초반 loss 2.5에서 거의 즉시 0.1~0.2 수준으로 떨어진다. Stage 1에서 이미 음성 이해 능력이 갖춰진 상태이고, Qwen3-4B 자체가 tool use를 할 줄 아는 모델이라 LoRA로 살짝 방향만 잡아주면 되는 것이다.
결과
Sori 데모 영상
날씨 질의 음성 예시 (ElevenLabs TTS)
모델은 HuggingFace에 공개해두었다:
- Seungyoun/Sori-4B-Base — Stage 1 alignment checkpoint
- Seungyoun/Sori-4B-FC — Function Calling 모델
마치며
이번 실험을 통해 알게 된 것들:
- 한국어 음성 410만 샘플, 6,000 스텝이면 기본적인 alignment가 가능하다
- Projection layer 12M 파라미터만으로도 음성-텍스트 정렬은 충분히 학습된다
- Loss 곡선에서 2k 스텝 부근의 phase transition이 관찰된다 — alignment가 갑자기 일어나는 순간이 있다
- Function Calling은 LoRA 350 스텝이면 충분하다 — base LLM의 tool use 능력이 이미 있으니까
물론 한계는 있다. 아직 실시간 스트리밍은 안 되고, 음성의 감정이나 톤을 활용하는 것도 추후 과제다. 하지만 한국어 Speech LLM의 훈련 다이나믹스에 대한 감을 잡을 수 있었고, 데이터 규모 대비 어디까지 가능한지에 대한 하나의 데이터 포인트를 남길 수 있었다고 생각한다.
코드와 모델은 모두 공개되어 있으니 관심 있으면 직접 돌려보시길.